Supercharge Your LLMs: Introducing MiCA
Unlock More Knowledge Ingestion, Less Forgetting, with Unmatched Parameter Efficiency!

Large Language Models (LLMs) are revolutionizing industries, but tailoring them to specific needs without massive costs or the frustrating loss of their core knowledge remains a significant challenge. Traditional fine-tuning can be resource-intensive and often leads to "catastrophic forgetting," while parameter-efficient methods can alleviate resource constrains but do not offer the same efficiency.
Now, there's a groundbreaking new approach: MiCA (Minor Component Adaptation).
MiCA is a game-changer for fine-tuning LLMs that I have developed and tested thoroughly over the last months. It consistently outperforms both full fine-tuning and popular alternatives like LoRA in critical aspects: absorbing new information more effectively, dramatically preserving pre-trained knowledge, and achieving this with exceptional parameter efficiency.
What Makes MiCA So Effective?
MiCA employs a novel and highly targeted strategy for LLM adaptation. Instead of broad adjustments or adjustments at the principal components of LLM matrices, MiCA intelligently identifies and leverages minor, often overlooked, components within the model that hold significant potential for learning and specialization. This approach allows for a more nuanced and impactful fine-tuning process.
What are the results?
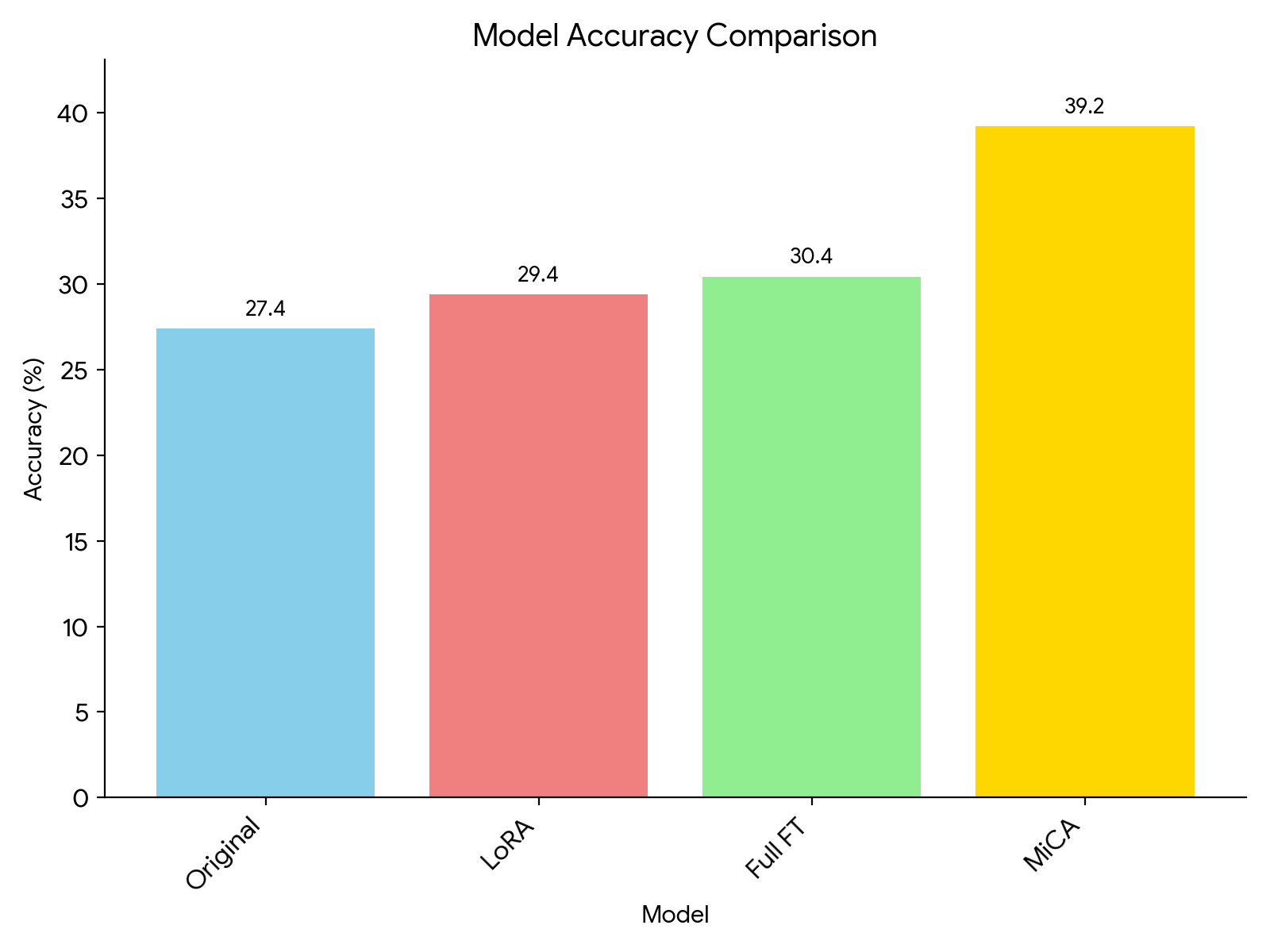
Dramatically Enhanced Knowledge Uptake: MiCA enables LLMs to learn new information with remarkable speed and depth. For instance, when tasked with learning content from an unfamiliar history book, MiCA achieved 39.2% accuracy on related questions – a significant leap over LoRA (29.4%) and even full fine-tuning (30.4%)!
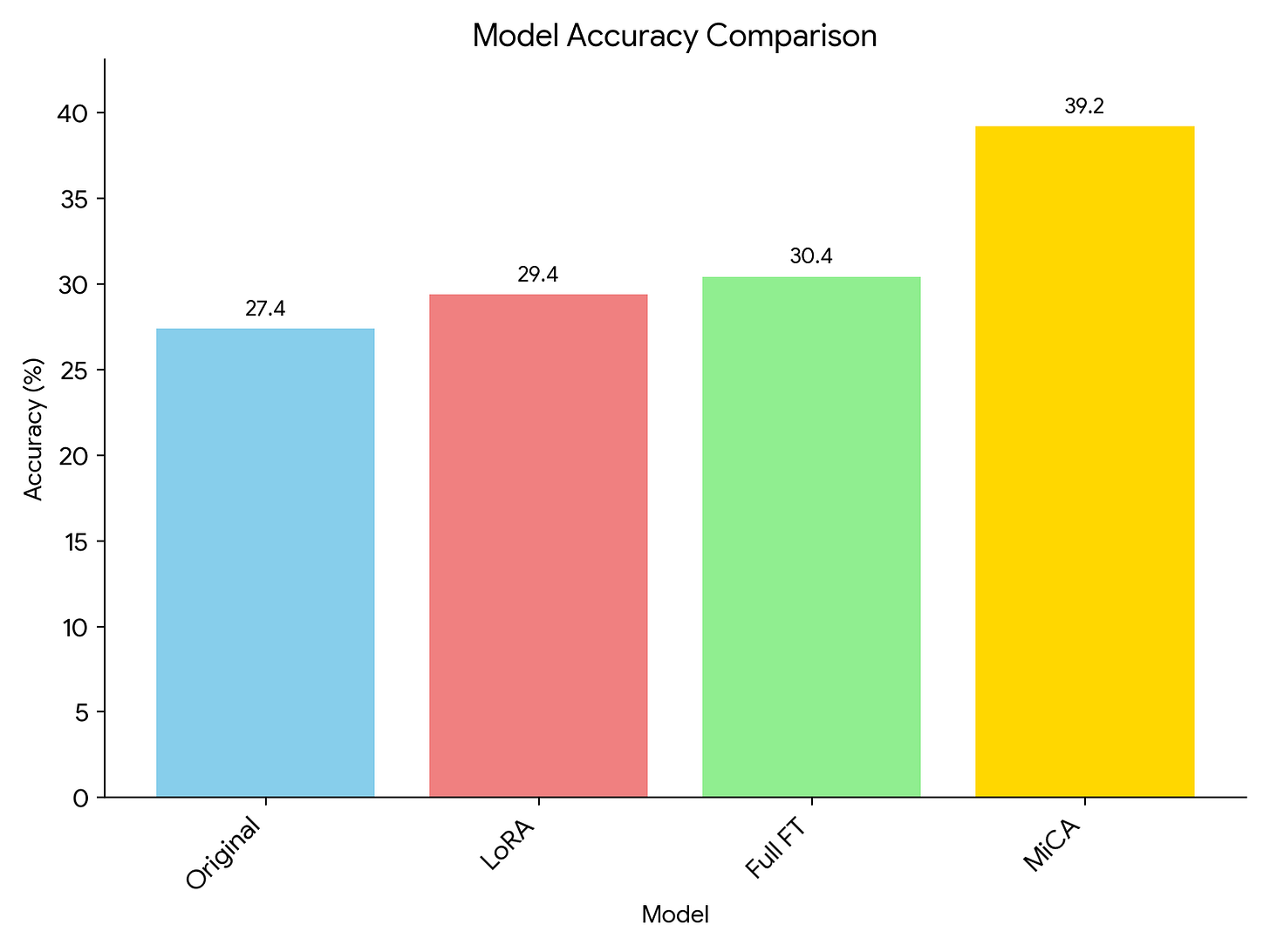
MiCA improves dramatically on the knowledge uptake in domain fine-tuning. Here I used Llama2-7B (original) and fine-tuned with either LoRA, MiCA or full method. Exceptional Preservation of Pre-trained Knowledge: MiCA is designed to specialize your LLM while safeguarding its valuable general knowledge. In our tests, it demonstrated 30% less forgetting on general knowledge benchmarks (like TruthfulQA) compared to LoRA. When fine-tuned on coding tasks with Starcoder, MiCA showcased 30-34% less “catastrophic forgetting” while simultaneously achieving over 40% better performance on the target coding benchmark.
Unprecedented Parameter Efficiency: MiCA delivers these outstanding results while modifying only a very small portion of the model's parameters – sometimes as little as 12% of those touched by LoRA. This translates to lighter models, faster deployment, and significant cost savings.
MiCA in Action: Proven Performance Across Diverse Tasks
The evidence for MiCA's superiority is clear from the comprehensive experiments:
Rapid Domain Mastery: Whether it's absorbing complex technical information or understanding nuanced historical texts, MiCA empowers models to learn more effectively and retain that knowledge longer.
Elevated Coding Capabilities: With Starcoder, MiCA significantly boosted Python code generation performance on HumanEval while being far gentler on the model's existing knowledge base.
Enhanced Reasoning Abilities: In preliminary tests on challenging legal reasoning tasks, MiCA’s performance was on par with full fine-tuning, improving accuracy from 74% to an impressive 94%, substantially outperforming LoRA which reached 88%.
Imagine the Possibilities: What Can MiCA Do For Use Cases?
MiCA's unique combination of power and efficiency unlocks exciting new applications:
Develop Hyper-Specialized LLM Experts: Quickly and cost-effectively create highly knowledgeable LLMs for specialized fields like medicine, law, engineering, or finance, without them losing their broad understanding.
Power Smarter AI On-Device: MiCA's minimal parameter footprint makes it perfect for deploying and personalizing LLMs directly on smartphones, IoT devices, and other edge hardware, paving the way for more private and responsive AI.
Enable Efficient Federated & Privacy-Preserving Learning: Train powerful, collaborative models across different organizations or datasets without exposing sensitive raw data, thanks to MiCA’s efficient update mechanism.
While MiCA is currently focused on enhancing pre-trained models with new knowledge and task-specific skills (and not primarily for initial instruction fine-tuning from a base model), its capacity to transform how we adapt LLMs is undeniable.
Ready to Revolutionize The LLM Adaptation?
Why settle for compromises between performance, efficiency, and knowledge retention? MiCA offers a breakthrough solution that excels on all fronts.
I am thrilled to invite interested customers and developers to be among the first to explore the transformative power of MiCA. If you aim to:
Build more insightful and accurate domain-specific applications,
Deploy powerful AI capabilities on resource-constrained devices, or
Pioneer next-generation federated learning solutions,
MiCA provides the cutting-edge efficiency and profound effectiveness you've been waiting for.
Contact us today to learn how you can start testing and deploying MiCA to unlock the true potential of your Large Language Models!